
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- node.js
- Babel
- For
- laravel
- CentOS
- nginx
- 블레이드 템플릿
- rabbitmq
- javascript
- Go
- linux
- deep learning
- Machine Learning
- SQL
- Switch
- React
- nodejs
- mariadb
- Node
- Backbone.js
- php
- NCP
- AWS
- 기초 수학
- docker
- Redis
- fastapi
- Redux
- webpack
- python
- Today
- Total
개발일기
기초 수학 - 특이값 분해(SVD)를 활용한 이미지 압축 본문

SVD Image Compression
특이값 분해 활용을 위해 먼저 matplotlib을 활용하여 이미지 하나를 출력시킨다.
# Singular Value Decomposition
from PIL import Image, ImageFile
import matplotlib.pyplot as plt
# ImageFile.LOAD_TRUNCATED_IMAGES = True # image file is truncated (2 bytes not processed)
!wget <https://i2.pickpik.com/photos/900/201/265/korea-seoul-jongno-city-c00898e0e8f0998492a96e0c987a672e.jpg>
img = Image.open('korea-seoul-jongno-city-c00898e0e8f0998492a96e0c987a672e.jpg')
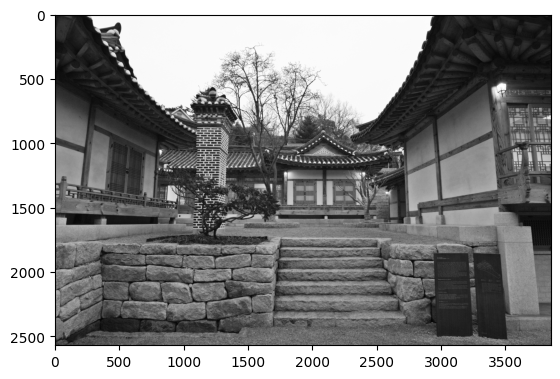
plt.imshow(img) # 원본 이미지
img = img.convert('LA')
plt.imshow(img) # 회색빛으로 변환

matplotlib: matplotlib은 데이터를 시각화할 수 있는 하나의 도구다. matplotlib을 활용하여 이미지 데이터를 시각화한다.
! wget: wget은 웹사이트에서 HTTP, HTTPS, FTP 프로토콜 등을 통해 콘텐츠를 가져올 수 있는 리눅스의 명령어다. 앞에 !를 사용하면 리눅스 명령어를 실행할 수 있다. wget으로 이미지를 가져온다.
plt.imshow(): 가져온 이미지를 plt 차트에 표시한다.
이미지는 RGB로 이뤄져있다. 즉, 3개의 행렬이 곂쳐서 표현된다는 뜻이다. 이를 1개의 행렬로 단순화하기 위해 회색빛으로 변환한다. convert()에 LA를 추가하면 회색빛으로 변환된다.
print(img_np.shape) # 이미지 행렬
# (2570, 3854)
shape로 이미지 행렬의 크기를 살펴보면 가로 3854, 세로 2570으로 이뤄져있다. 단위는 픽셀이며 3854x2570 크기의 이미지라는 것을 의미한다. 행렬 요소는 이미지의 명암에 따라 다양한 수로 구성되어 있다. 어두운 부분은 0에 가까운 수를 가지고 상대적으로 밝은 부분은 255가 가까운 수를 가진다. 지금은 단순히 색상의 3계층에서 R계열을 활용해 표현하고 있기에 회색빛으로 나온다.
Numpy로 변환
img_np = np.array(list(img.getdata(band=0)), float)
img_np.shape = (img.size[1], img.size[0])
img_np = np.matrix(img_np)
plt.imshow(img_np, cmap='gray') # 원본 이미지와 동일
이미지를 numpy에서 활용할 수 있게 numpy 행렬로 변환한다.
getData(): 이미지를 픽셀 값을 가진 객체로 반환한다.
band: 반환할 RGB를 나타낸다. 0은 R, 1은 RG, 2는 RGB로 band 수가 늘어날 때마다 색상 행렬이 하나씩 늘어난다. 이미지를 단순하게 회색빛으로 표현할 예제이기 때문에 band를 0으로 설정한다.
float: numpy배열의 데이터 타입을 지정한다. float으로 지정한다.
SVD 진행
생성된 numpy 행렬로 특이값 분해를 진행한다.
U, S, V = np.linalg.svd(img_np) # 특이값 분해
img_svd = np.matrix(U[:, :1]) * np.diag(S[:1]) * np.matrix(V[:1, :])
plt.imshow(img_svd, cmap='gray')
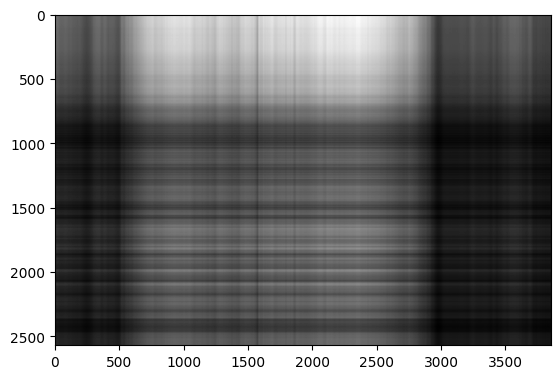
특이값 분해를 한 후, 각 특이벡터를 내림차순 정렬한다. 내림차순으로 정렬하는 이유는 데이터의 중요도를 반영하기 위함이다. 첫번째부터 중요 정보를 담고 있으면 차원 축소를 진행할 때 원활하게 진행할 수 있으며 덜 중요한 데이터는 후순위로 밀려나 특이값 분해에 적은 영향을 끼치기 때문이다. 좌특이벡터, 대각행렬, 우특이벡터를 각각 내림차순으로 정렬하면 차원 축소된 이미지를 바탕으로 이미지 복원을 쉽게 진행해 나갈 수 있다.
우선 계수를 1로 정한 후, 내림차순을 진행하였다. 하나의 벡터와 한개의 고유값으로 이미지가 구성되기에 기존 이미지와 매우 다른 이미지가 나온다.
이미지 복원
for문에 여러개의 계수를 넣고 이미지가 어떻게 복원되는지 확인해보자
for k in [2, 4, 8, 16, 32, 64, 128]:
img_svd = np.matrix(U[:, :k] * np.diag(S[:k]) * np.matrix(V[:k, :]))
plt.imshow(img_svd, cmap='gray')
title = "SVD k = %s" % k
plt.title(title)
plt.show() # SVD 결과 이미지
plt.imshow(img_np, cmap='gray')
plt.title('Original Image')
plt.show() # 원본 이미지

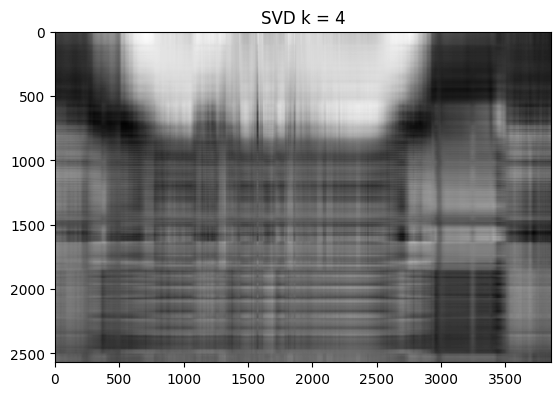






계수가 증가할 때 마다 이미지가 선명해지면서 기존 이미지 형상과 유사해진다. 16부터 대략적인 이미지의 느낌이 나며 32부터는 이미지의 형태가 보이기 시작한다. 계수가 64 또는 128일 때, 이미지가 꽤나 선명해진다. 이는 특이벡터 128개로 이미지 압축을 성공적으로 진행했다는 것을 의미한다.
이미지 압축 결과 확인
numpy_image_elements = img_np.shape[0] * img_np.shape[1]
svd_image_elements = img_svd.shape[0] * 128 + 128 + img_svd.shape[1] * 128
print("Numpy Image Vectors: ", numpy_image_elements)
print("SVD Image Vectors: ", svd_image_elements)
print("Res: ", numpy_image_elements / svd_image_elements)
Numpy Image Vectors: 9904780
SVD Image Vectors: 822400
Res: 0.08303061754021795
기존 이미지는 9904780개의 요소로 구성되어 있고 SVD된 이미지는 822400개의 요소로 구성되어 있다. SVD 이미지는 대략 8%의 기존 이미지에 비해 압축되어 있는 상태를 의미한다. 즉 기존 이미지에서 8%의 데이터만 사용하여 기존 이미지와 매우 유사한 이미지를 표현할 수 있다. SVD를 통해 입력값을 줄여 연산 과정을 상당히 줄일 수 있다.
참고 사이트:
https://github.com/jonkrohn/ML-foundations/blob/master/notebooks/2-linear-algebra-ii.ipynb
ML-foundations/notebooks/2-linear-algebra-ii.ipynb at master · jonkrohn/ML-foundations
Machine Learning Foundations: Linear Algebra, Calculus, Statistics & Computer Science - jonkrohn/ML-foundations
github.com
Image Compression via SVD 항목
https://www.youtube.com/watch?v=H7qMMudo3e8
https://colab.research.google.com/drive/16b6JqgXZ5RwboHYFDbJT__lr8HIbM0Bb?usp=sharing
특이값 분해 활용.ipynb
Colab notebook
colab.research.google.com
'AI > 기초 수학' 카테고리의 다른 글
| 기초 수학 - PCA(주성분 분석) (0) | 2024.05.01 |
|---|---|
| 기초 수학 - Moore Penrose Pseudo Inverse 유사 역행렬 (0) | 2024.04.21 |
| 기초 수학 - 특이값 분해(SVD) (0) | 2024.04.13 |
| 기초 수학 - 고유값의 특성 (0) | 2024.03.31 |
| 기초 수학 - 행렬 판별식 (0) | 2024.03.31 |



