
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- laravel
- Babel
- For
- 기초 수학
- mariadb
- deep learning
- php
- SQL
- linux
- Switch
- Backbone.js
- Machine Learning
- Redis
- phpredis
- javascript
- React
- webpack
- Redux
- NCP
- AWS
- rabbitmq
- nodejs
- nginx
- Go
- CentOS
- python
- 블레이드 템플릿
- Node
- docker
- fastapi
- Today
- Total
개발일기
머신 러닝 - IQR 이상치(Outliers) 제거 본문

이상치 제거란?
이상치 제거란 데이터셋의 데이터를 분석하는 과정에서 데이터셋 내에 존재하는 이상치(Outliers)를 제거하는 과정을 의미한다. 여기서 이상치란 데이터셋의 데이터가 일정 패턴으로 분포되어 있을 때, 이 분포에 속해있지 않고 왼쪽, 오른쪽 한쪽으로 극단적으로 치우쳐 있는 데이터를 의미한다. 이상치로 인해 데이터의 평균과 분산에 큰 영향을 끼치며 분석 결과가 왜곡된 형태로 나타날 수 있다. 데이터가 왜곡되면 모델의 예측 성능이 저하되며 비정상적인 통계 결과가 나오게 된다.
Histogram
히스토그램을 통해 이상치가 존재하는지 파악한 후, Boxplot을 통해 이상치의 규모를 시각화 한 후, 이상치 제거를 진행한다. 먼저 California Housing 데이터셋을 예제로 활용하여 각 특성을 히스토그램으로 출력한다. 히스토그램은 각 특성의 데이터 분포를 대략적으로 나타낸다. 중요한 특성 6개만 특정하여 데이터를 확인할 수 있다.
# Show California Housing Histogram
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.datasets import fetch_california_housing
import matplotlib.pyplot as plt
# Load the California housing dataset
housing = fetch_california_housing(as_frame=True)
housing = housing.frame
# Data Histogram
outliers_list = ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup'] # 중요 특성 6가지
housing.hist(outliers_list, bins=50, figsize=(12,8))
plt.show()

- MedInc: 중간 소득은 대부분 낮은 쪽에 집중적으로 분포되어 있다. 높은 소득을 가진 데이터는 오른쪽 끝에 분포되어 있다. 극단적으로 높은 소득은 이상치로 분류될 수 있다.
- HouseAge: 주택이 지어지고 몇년이 지났는지를 나타낸다. 50년도 이상부터는 상한선인 끝부분에 몰려있다. 이는 이상치로 분류될 수 있다.
- AveRooms: 평균 방 수는 2~4개인데 이보다 더 높은 10개의 방을 가졌다고 나오는 데이터는 이상치로 분류될 수 있다.
- AveBedRms: AveRooms와 비슷한 유형이다.
- Population: 인구 수는 보통 낮은 값에 집중되어 분포되어 있다. 이와 다르게 극단적으로 높은 값에 있는 데이터는 이상치로 분류될 수 있다.
- AveOccup: 평균 가구원 수는 1~4명에 집중되어 분포되어 있다. 이와 다르게 극단적으로 높은 구성원 값을 가진 데이터는 이상치로 분류될 수 있다.
Boxplot
데이터 분포를 대략적으로 확인한 후, Boxplot을 활용하여 각 특성의 이상치를 규모를 자세하게 확인할 수 있다. Boxplot은 IQR(Interquartile Range)을 시각적으로 표현하여 데이터의 분포와 이상치를 표현한다. Boxplot의 핵심요소인 IQR은 사분위수 범위를 뜻한다. 데이터의 중앙값(Median)인 정중앙을 기준으로 전체 데이터의 상위 25%와 하위 25%를 제외한 나머지 50%의 데이터가 차지하는 범위를 나타낸다.
import seaborn as sns
fig, axes = plt.subplots(1, 1, figsize=(5, 5))
sns.boxplot(data=housing, x='HouseAge')
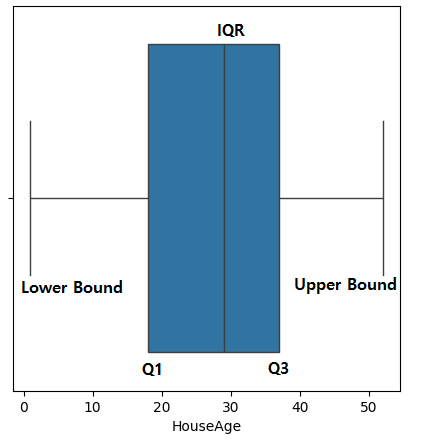
- 제 1사분위수(Q1): 데이터의 하위 25% 지점을 의미한다.
- 제 3사분위수(Q3): 데이터의 상위 25% 지점을 의미한다.
- IQR: $ Q3 - Q1 $ 로 데이터의 중간 50%가 차지하는 범위를 의미한다. IQR이 크면 중간 데이터가 넓게 퍼져있음을 의미하며 IQR이 작으면 중간 데이터가 좁게 분포되어 있음을 의미한다.
파란 사각형의 가장 왼쪽 선은 하위 25% 지점으로 Q1이다. 가장 오른쪽 선은 상위 25%지점으로 Q3이다. 마지막으로 사각형 중앙에 있는 선은 중앙값을 나타내는 선이다. IQR은 Q1과 Q3 사이의 범위로 $ IQR = Q3 - Q1 $ 로 표현된다.
0과 50 주변에 있는 각각의 선은 이상치를 판별하는 하한선(Minimum), 상한선(Maximum)을 의미한다.
- 하한선(Lower Bound): Q1 - 1.5 X IQR로 설정된다. 이보다 작은 값들은 이상치로 간주된다.
- 상한선(Upper Bound): Q3 + 1.5 X IQR로 설정된다. 이보다 큰 값들은 이상치로 간주된다.
IQR 계산
Q1, Q3지점에서 IQR보다 1.5배 크거나 작은 지점을 벗어난 값들은 정상적인 분포에서 벗어난 것으로 간주되며 극단적인 값으로 인식된다.
import numpy as np
Q1, Q3 = np.percentile(housing['HouseAge'], [25, 75])
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
minimum_value = np.amin(housing['HouseAge'])
maximum_value = np.amax(housing['HouseAge'])
print('Q1: ', Q1)
print('Q3: ', Q3)
print('IQR: ', IQR)
print('Lower Bound: ', lower_bound)
print('Upper Bound: ', upper_bound)
print('Minimum Value: ', minimum_value)
print('Maximum Value: ', maximum_value)
"""
Q1: 18.0
Q3: 37.0
IQR: 19.0
Lower Bound: -10.5
Upper Bound: 65.5
Minimum Value: 1.0
Maximum Value: 52.0
"""
Boxplot에 있는 HouseAge 특성의 Q1, Q3, IQR, 하한선과 상한선을 계산한 코드이다. 하한선과 상한선의 값이 데이터의 최소값, 최대값을 벗어날 경우 데이터의 최소값, 최대값으로 하한선과 상한선이 표시된다. IQR을 통해 HouseAge의 이상치를 탐지한 이상치가 없다는 결론이 도출된다.
Dataset Boxlplot
import seaborn as sns
fig, axes = plt.subplots(3, 2, figsize = (10, 10))
for i, item in enumerate(outliers_list):
row = i // 2
col = i % 2
sns.boxplot(data=housing, x=item, ax=axes[row, col])
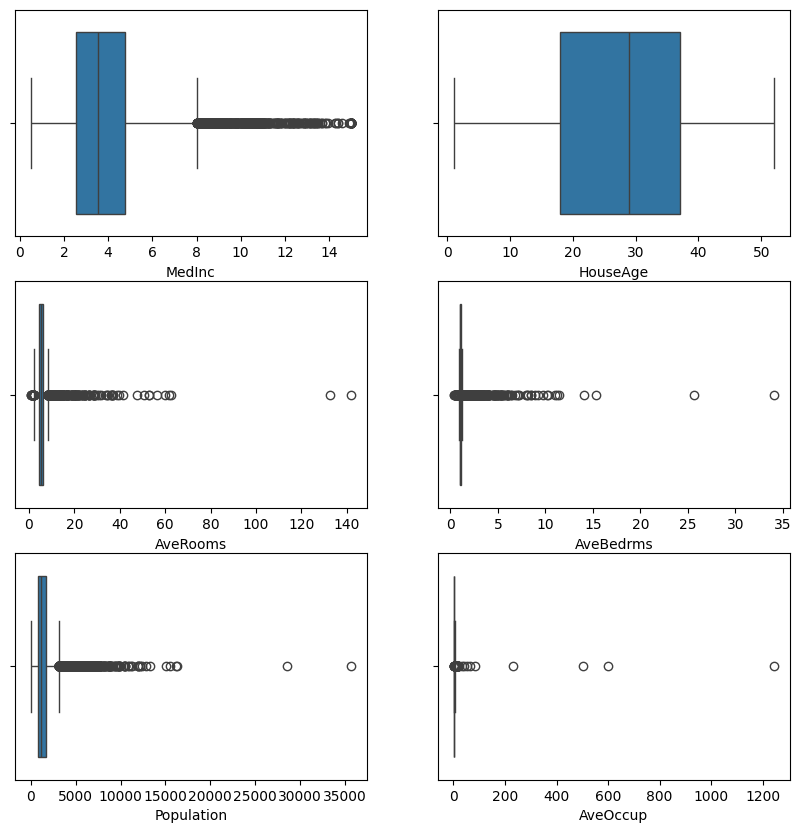
HouseAge이외에 다른 특성들의 Boxplot도 출력할 수 있다. HouseAge를 제외한 다른 특성들은 이상치가 표시된 것을 확인할 수 있다.
이상치 개수 확인
def count_outliers(outliers_list):
for i, item in enumerate(outliers_list):
Q1, Q3 = np.percentile(housing[item], [25, 75])
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = len(housing[(housing[item] < lower_bound) | (housing[item] > upper_bound)])
print(f'{item}: {outliers}')
count_outliers(outliers_list)
"""
MedInc: 681
HouseAge: 0
AveRooms: 511
AveBedrms: 1424
Population: 1196
AveOccup: 711
"""
각 특성에 존재하는 이상치의 개수를 확인하면 꽤나 많은 이상치가 존재한다는 것을 확인할 수 있다. 모델을 학습시키기 전에 이 이상치들을 제거해줘야 성능 좋은 모델을 만들 수 있다.
이상치 제거
def remove_outliers(outliers_list):
global housing
list_of_masks_for_outlier_removal = []
for i, item in enumerate(outliers_list):
Q1, Q3 = np.percentile(housing[item], [25, 75])
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
lower_data = housing[item] >= lower_bound
upper_data = housing[item] <= upper_bound
housing = housing = housing[lower_data & upper_data]
remove_outliers(outliers_list)
print(f'After Remove Outliers: {housing.shape}')
# After Remove Outliers: (16813, 9)Lower Bound보다 낮은 값을 가진 데이터와 Upper Bound보다 높은 값을 가진 데이터를 제거한 후 다시 데이터셋에 대입하면 이상치가 제거된 데이터셋이 나타난다.
참고 사이트:
https://colab.research.google.com/drive/12fX_F7SknqRbczul8JEcGN_D7dO0YuXn?usp=sharing
Remove Outliers.ipynb
Colab notebook
colab.research.google.com
https://www.statology.org/interquartile-range-python/
How to Calculate The Interquartile Range in Python
A simple explanation of how to calculate the interquartile range in Python.
www.statology.org
How matplotlib calculate the value of lower and upper extreme in boxplot?
I tried to understand how matplotlib draws a graph. This is the code that I write. import matplotlib.pyplot as plt import pandas as pd age=[20,22,22,23,23,23,23,24,24,24,24,26,26,30] df=pd.DataFr...
stackoverflow.com
Negative inner fence. How can you find the outlier using 1.5 x IQR?
I'm trying to find outliers using 1.5 x interquartile range but I'm getting a negative value for the lower bound. I found Q3 and Q1 which are 13.30 & 3.00 respectively but for the lower bound i...
stats.stackexchange.com
'AI > Deep Learning - Machine Learning' 카테고리의 다른 글
| AI - tensorflow 전처리 함수를 활용한 연산 최적화 (0) | 2025.01.01 |
|---|---|
| AI - Dropout을 통한 과대적합 방지 (0) | 2025.01.01 |
| 딥러닝 - 합성곱 신경망을 이용한 mnist 데이터 예측 모델 (0) | 2024.12.29 |
| 딥러닝 - 합성곱 신경망(CNN) (0) | 2024.12.27 |
| 머신 러닝 - California Housing Price Prediction(Regression) (0) | 2024.08.18 |



