
- 분류 전체보기 (189)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- linux
- deep learning
- webpack
- 블레이드 템플릿
- laravel
- rabbitmq
- 기초 수학
- Go
- Backbone.js
- Node
- docker
- SQL
- nodejs
- CentOS
- phpredis
- python
- Redux
- AWS
- javascript
- mariadb
- For
- fastapi
- Redis
- Babel
- Switch
- Machine Learning
- nginx
- React
- NCP
- php
- Today
- Total
개발일기
딥러닝 - 합성곱 신경망(CNN) 본문

합성곱 신경망(Convolution Neural Network)
합성곱 신경망은 데이터가 가진 특징들의 패턴을 학습하는 알고리즘으로 이미지나 영상 데이터를 처리하는데 주로 사용된다. 이를 사용하는 예시로는 이미지 분류(Image Classification)과 객체 탐지(Object Detection) 등이 있다. 이미지 분류는 이미지의 특징을 추출하여 고양이와 강아지 사진 중에서 어떤 사진이 고양이인지 강아지인지 분류해낸다 . 객체 탐지는 이미지에서 특정한 객체를 인식하고 위치를 파악하여 경계 박스로 객체를 탐지해낸다.
이미지 구성
# Tensorflow
import tensorflow as tf
mnist = tf.keras.datasets.mnist # mnist 이미지 데이터 가져오기
(x_train, y_train), (x_test, y_test) = mnist.load_data() # train: 훈련용, test: 테스트용
print(x_train.shape, y_train.shape) # (60000, 28, 28) (60000,)
print(x_test.shape, y_test.shape) # (10000, 28, 28) (10000,)
"""
Downloading data from <https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz>
11490434/11490434 ━━━━━━━━━━━━━━━━━━━━ 0s 0us/step
(60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
"""- mnist.load_data(): mnist 데이터셋을 로드한다, train이 붙은 것은 학습용 데이터와 레이블을 나타내며 test가 붙은 것은 테스트용 데이터와 레이블을 나타낸다.
# Pytorch
import torch
from torchvision import datasets, transforms
train_data = datasets.MNIST(root='./data', train=True, download=True, transform=transforms.ToTensor()) # 학습용 데이터
test_data= datasets.MNIST(root='./data', train=False, download=True, transform=transforms.ToTensor()) # 검증용 데이터
print(len(train_data), len(test_data)) # 60000 10000
image, lable = train_data[0]
print(image.shape) # torch.Size([1, 28, 28])- root: 데이터의 저장 경로를 나타낸다.
- train: True로 설정하면 학습용 데이터를 불러오며 tensorflow keras의 x_train, y_train과 동일하다. False로 설정하면 테스트용 데이터를 불러오며 tensorflow keras의 x_test, y_test와 동일하다.
- downlaod: True로 설정하면 로컬에 데이터가 없을 경우 데이터셋 다운로드를 진행한다. False로 설정하면 로컬에 데이터셋이 있다고 가정하고 로컬에서 데이터셋을 불러온다.
- transform: 데이터셋으로 불러온 이미지 데이터를 텐서 형식으로 변환한다.
- ToTensor(): 데이터셋의 정규화를 진행한다. ToTensor()는 Min-Max 정규화를 사용한다.
train_data와 test_data의 길이를 출력하면 tensorflow keras와 동일하게 60000, 10000개의 데이터를 가져온 것을 확인할 수 있다.
# Tensorflow - 이미지 출력
import matplotlib.pyplot as plt
def plot_image(data, idx):
plt.figure(figsize=(5, 5))
plt.imshow(data[idx], cmap='gray')
plt.axis('off')
plt.show()
plot_image(x_train, 0) # 첫번째 데이터 시각화# Pytorch - 이미지 출력
import matplotlib.pyplot as plt
plt.figure(figsize=(5, 5))
plt.imshow(image.squeeze(), cmap='gray')
plt.axis('off')
plt.show()
- squeeze(): 크기가 1인 차원을 제거한다. image는 (1, 28, 28) 형태이므로 이미지를 출력하기 위해선 첫 번째 차원을 제거한다. mnist는 흑백 이미지 데이터이므로 첫 번째 차원을 제거한 후 출력할 수 있다.
pytorch는 데이터를 가져올 때 ToTensor()를 통해 Min-Max Normalization을 진행하였다. tensorflow 데이터도 동일하게 Min-Max Normalization을 진행한다.
# Tensorflow - 데이터 정규화(Normalization)
print('--- Before Normalization---')
print(x_train.min(), x_train.max())
print(x_test.min(), x_test.max())
# 정규화 진행
x_train = x_train / x_train.max()
x_test = x_test / x_test.max()
print('--- After Normalization---')
print(x_train.min(), x_train.max())
print(x_test.min(), x_test.max())
"""
--- Before Normalization---
0 255
0 255
--- After Normalization---
0.0 1.0
0.0 1.0
"""
3채널(RGB) 이미지
이미지는 0과 255사이의 숫자로 이루어져 있다. 흑백 이미지를 예시로 들면 0은 검은색을 의미하고 255는 흰색을 나타낸다. 이 둘 사이에 존재하는 10, 100, 125와 같은 숫자들은 회색빛이며 숫자가 클수록 해당 색상을 더 강하게 표현한다. 흑백 이미지가 아닌 색상이 있는 이미지는 R(Red), B(Blue), G(Green)로 이루어져 있으며 이 또한 마찬가지로 0과 255 사이의 숫자로 나타낸다.
import requests
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
from io import BytesIO
# URL 이미지 로드
url = "<https://cdn.pixabay.com/photo/2024/02/28/07/42/european-shorthair-8601492_1280.jpg>"
response = requests.get(url)
image = Image.open(BytesIO(response.content))
# NumPy 배열로 변환
image_np = np.array(image)
red_channel = image_np[:, :, 0] # R 채널 추출
green_channel = image_np[:, :, 1] # G 채널 추출
blue_channel = image_np[:, :, 2] # B 채널 추출
image_rgbs = [red_channel, green_channel, blue_channel]
image_cmaps = ['Reds', 'Greens', 'Blues']
fig, axes = plt.subplots(1, 3, figsize=(5, 5))
for i, ax in enumerate(axes.flat):
ax.imshow(image_rgbs[i], image_cmaps[i])
ax.axis('off')
plt.tight_layout()
plt.show() # RGB images show
plt.figure(figsize=(6, 5))
plt.imshow(image_np)
plt.axis('off')
plt.title('original')
plt.show() # original image show이미지는 위와 같이 RGB 이미지가 하나로 결합되어 표현된다.


이와같은 이미지들은 CNN을 통해 학습하고 활용하려면 합성곱(Convolution), 채널(Channel), 스트라이드(Stride), 패딩(Padding), 풀링(Pooling) 등에 대한 간단한 지식이 필요하다.
합성곱(Convolution)
딥러닝에서 합성곱 연산은 입력 이미지에 대하여 일반적으로 정방형 크기의 필터를 사용하여 입력 이미지의 특성을 추출한다. 추출된 특성을 특성맵(feature map)이라 칭하고 이를 통해 모델 학습에 사용하면 좋은 성능을 보일 수 있다.
입력 이미지를 shape로 출력하면 (세로, 가로) 순서로 출력된다. 이미지를 행렬로 표현할 때는 (세로, 가로) 순서가 일반적인 관례이며 딥러닝 프레임워크에서도 이미지를 행렬로 표현할 때, 행이 세로를, 열이 가로를 나타내기 때문이다.
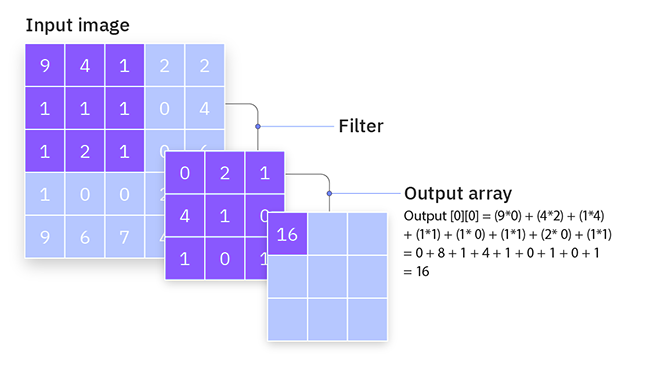
입력 이미지가 5x5이고 필터가 3x3로 가정하자. 필터가 좌측 상단의 입력 이미지부터 오른쪽 방향을 향해 차례대로 이동한다. 이동을 하기 전에 입력 이미지와 필터가 겹쳐지는 부분에서 합성곱 연산을 수행한다.
$ \begin{pmatrix} 9 & 4 & 1 \\ 1 & 1 & 1 \\ 1 & 2 & 1 \\ \end{pmatrix} $ 입력 이미지가 이와 같은 행렬이고 필터는
$ \begin{pmatrix} 0 & 2 & 1 \\ 4 & 1 & 0 \\ 1 & 0 & 1 \\ \end{pmatrix} $ 이와 같은 행렬이다. 이제 이를 곱하고 더해야 하는데 입력 이미지와 필터를 겹쳤을 때, 일치하는 부분끼리 곱셈을 진행한다. 입력 이미지의 9는 필터의 0과 겹치므로 0 x 9, 입력 이미지의 4는 필터의 2와 겹치므로 4 x 2… 순으로 겹치는 모든 부분의 곱셈을 진행한 후 최종 결과를 더한다. 더해진 결과는 해당 필터의 특성맵 요소가 된다. 필터가 오른쪽 끝 부분까지 이동하게 되면 다음 이동은 아래로 한 칸 이동하고 기존과 똑같이 왼쪽 → 오른쪽 순으로 슬라이딩을 하며 합성곱 연산을 진행한다. 합성곱 연산을 모두 진행하면 3 x 3 형태의 특성맵이 출력된다.
채널(Channel)
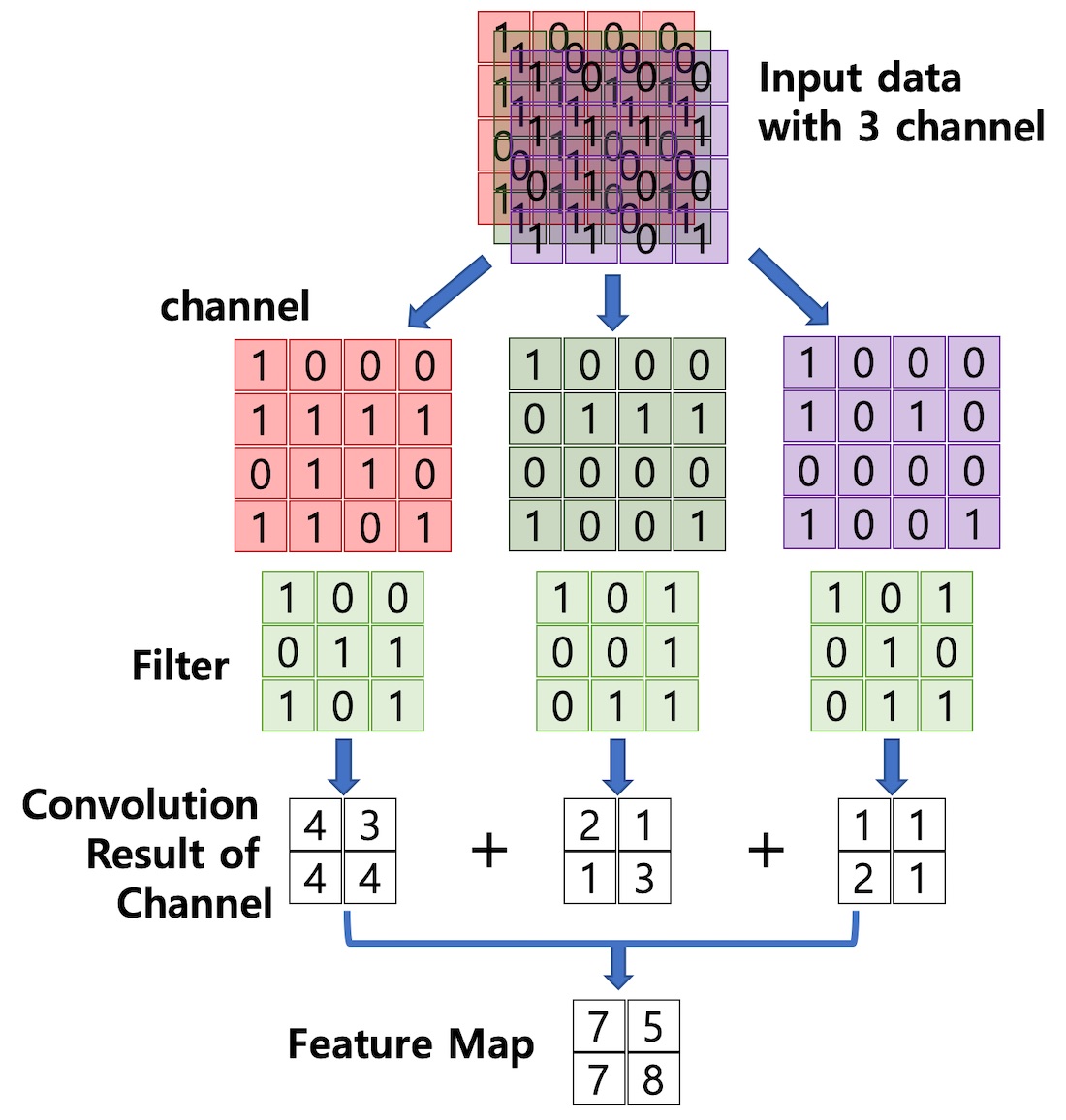
위의 예제와 다르게 컬러가 있는 입력 이미지는 RGB 3개의 채널을 가지게 된다. 여러개의 채널을 가진 입력 이미지에서의 합성곱 연산은 단일 채널때와 비슷하게 진행된다. 각 채널 개수만큼 필터가 생성되고 각각의 채널에 필터를 하나씩 적용하여 합성곱 연산을 수행한다. 채널이 3개면 이 과정을 3번 반복하게 되는데 각 채널의 특성맵을 모두 더하면 3채널 이미지의 최종 특성맵이 추출된다.
스트라이드(Stride)
필터는 기본적으로 입력 이미지의 좌측 상단을 기준으로 우측으로 이동하면서 합성곱 연산을 진행한다. 연산을 진행하면서 특성맵의 결과를 채워 나간다. 이때 이동하는 간격을 stride라고 정의하며 주로 1 또는 2로 정의하여 연산을 진행한다. 스트라이드가 1이면 필터를 우측으로 1픽셀씩 이동하며 연산을 진행한다. 만약 스트라이드가 2면 필터를 우측으로 2픽셀씩 이동하며 연산을 진행한다.
입력 이미지가 5 x 5, 필터가 3 x 3일 때, 스트라이드를 1로 정의하고 합성곱 연산을 진행하면 특성맵은 3 x 3 형태가 된다. 스트라이드를 2로 정의하면 특성맵은 2 x 2 형태가 된다.
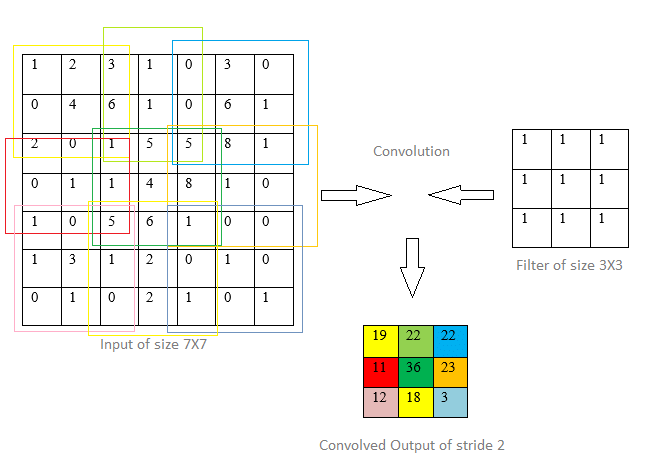
위 그림은 stride를 2로 설정했을 때 합성곱 연산의 결과이다. 2픽셀씩 건너뛰며 합성곱 연산을 진행하는 것을 확인할 수 있다.
패딩(Padding)
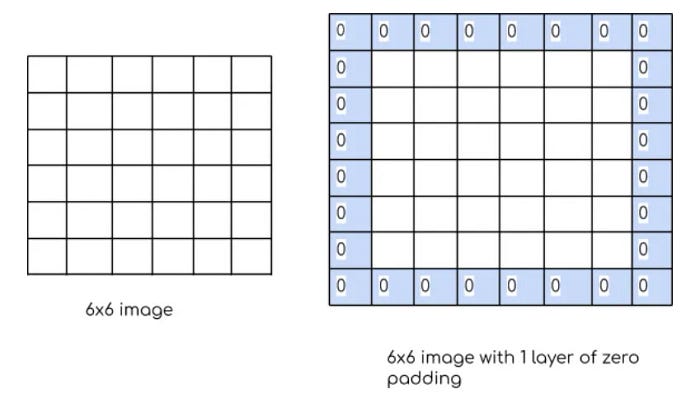
위의 예제를 바탕으로 입력 이미지를 5 x 5, 필터를 3 x 3으로 하면 특성맵은 3 x 3으로 가로, 세로 2픽셀이 줄어든다. 하지만 패딩(padding)을 적용하면 특성맵의 크기가 줄어들지 않고 입력 이미지와 같은 비율로 출력이 되게 할 수 있다. 즉, 패딩을 적용하면 입력 이미지 5 x 5와 동일한 크기의 특성맵을 추출할 수 있다. 즉 입력 이미지 가장자리에 값을 추가로 채워넣는 작업을 의미하며 패딩을 적용한만큼 이미지가 커지기 때문에 특성 맵의 크기를 조정할 수 있게된다.
특성맵의 크기
특성맵의 크기를 결정하는 스트라이드와 패딩의 값을 통해 특성맵의 크기를 구할 수 있다.
- Input height, Input width: 입력 이미지의 세로, 가로 크기(size)
- kernel height, kernel width: 커널(필터)의 세로 , 가로 크기(size)
- S: Stride
- P: Padding
- Output height, Output width: 특성맵의 세로, 가로 크기(size)
$ (Output Height, Output Width) = (\frac{Inner Height + 2P - Kernel Height}{S} + 1, \frac{Inner Width + 2P - Kernel Width}{S} + 1) $
필터가 처음 적용되는 위치를 계산에서 포함하기 위해 1을 더해준다. 입력 이미지의 세로, 가로 크기가 동일하다면 $ \frac{Inut Size + 2P - Kernel Size}{S} + 1 $ 하나로 계산이 가능하다.
입력 이미지가 7 x 7이고 필터가 3 x 3, stride가 2, padding이 1일 경우, 위의 계산 식을 통해 계산하면 특성맵의 크기는 7 x 7이 된다.
풀링(Pooling)
추출된 특성맵의 크기를 줄이기 위해 사용되는 연산이다. 풀링을 통해 이미지를 축소하면 연산량이 감소하게 된다. 연산량 감소로 인해 효율성이 향상되게 되며 중요한 데이터의 특징만 유지시켜 과적합을 방지할 수 있다. 즉, 풀링을 통해 모델의 성능 향상을 기대할 수 있다.
풀링의 종류에는 최대 풀링과 평균 풀링이 있다.
- 최대 풀링(Max Pooling): 영역 내의 최대 값을 출력 값으로 선택한다.
- 평균 풀링(Average Pooling): 영역 내의 값 중에서 평균 값을 출력 값으로 선택한다.

위의 이미지는 필터가 2 x 2 픽셀이고 stride가 2로 설정된 상태에서 풀링을 진행한 결과다. 필터를 슬라이드하면서 겹치는 영역의 최대 값을 특성맵 요소로 선택하는게 최대 풀링. 겹치는 영역의 평균 값을 특성맵 요소로 선택하는게 평균 풀링이다.
참고 사이트:
https://colab.research.google.com/drive/12PbFptj-y5YgJf8jhbJ_7pvNF2MRDaJJ?usp=sharing
CNN Basic.ipynb
Colab notebook
colab.research.google.com
https://www.mathworks.com/discovery/convolution.html
Convolution
Convolution is a mathematical operation that combines two signals and outputs a third signal. See how convolution is used in image processing, signal processing, and deep learning.
www.mathworks.com
https://www.mql5.com/en/articles/15259
Data Science and ML (Part 27): Convolutional Neural Networks (CNNs) in MetaTrader 5 Trading Bots — Are They Worth It?
Convolutional Neural Networks (CNNs) are renowned for their prowess in detecting patterns in images and videos, with applications spanning diverse fields. In this article, we explore the potential of CNNs to identify valuable patterns in financial markets
www.mql5.com
CNN, Convolutional Neural Network 요약
Convolutional Neural Network, CNN을 정리합니다.
taewan.kim
https://www.researchgate.net/figure/Convolution-Operation-with-Stride-value-2_fig3_350487754
https://ruhelalakshya.medium.com/convulational-padding-and-stride-59cb1b20c919
CONVULATIONAL PADDING AND STRIDE
WHAT IS CONVULATIONAL PADDING?
ruhelalakshya.medium.com
'AI > Deep Learning - Machine Learning' 카테고리의 다른 글
| AI - tensorflow 전처리 함수를 활용한 연산 최적화 (0) | 2025.01.01 |
|---|---|
| AI - Dropout을 통한 과대적합 방지 (0) | 2025.01.01 |
| 딥러닝 - 합성곱 신경망을 이용한 mnist 데이터 예측 모델 (0) | 2024.12.29 |
| 머신 러닝 - California Housing Price Prediction(Regression) (0) | 2024.08.18 |
| 머신 러닝 - IQR 이상치(Outliers) 제거 (0) | 2024.08.17 |



