
- 분류 전체보기 (189)

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- laravel
- For
- phpredis
- Redux
- python
- Node
- webpack
- php
- CentOS
- 블레이드 템플릿
- React
- mariadb
- Redis
- nginx
- AWS
- 기초 수학
- Switch
- fastapi
- linux
- Machine Learning
- Babel
- docker
- Backbone.js
- SQL
- rabbitmq
- deep learning
- Go
- javascript
- nodejs
- NCP
- Today
- Total
개발일기
딥러닝 - 합성곱 신경망을 이용한 mnist 데이터 예측 모델 본문
딥러닝 - 합성곱 신경망을 이용한 mnist 데이터 예측 모델
Flashback 2024. 12. 29. 22:54
이전 게시글을 통해 정규화시킨 mnist데이터셋 코드를 활용하여 간단한 합성곱 신경망 모델을 이미지를 분류할 수 있다.
1. 모델 생성
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation = 'relu', input_shape=(28, 28, 1), name='conv'), # convolution 적용, 32개의 필터 3 x 3 형태
tf.keras.layers.MaxPooling2D((2, 2), name='pool'), # MaxPooling 적용
tf.keras.layers.Flatten(), # 1차원으로 변환
tf.keras.layers.Dense(10, activation='softmax') # 정답 레이블이 0 ~ 9 사이의 값이기 때문에 노드 개수를 10으로 지정
])- Conv2D: 합성곱을 사용하기 위해 Conv2D 레이어를 사용한다.
- 32: 필터의 개수이다. 일반적으로 mnist와 같은 작은 이미지를 가진 간단한 데이터는 초기 필터를 32로 설정한다. 필터를 16으로 설정하여 학습 시간과 메모리에 대한 부담을 덜 수도 있다. 하지만 필터수가 많으면 더 다양한 특징을 학습시킬 수 있다는 장점을 가지고 있다.
- (3, 3): 필터의 크기이다. 위와 같은 이유로 적당한 크기인 (3, 3)으로 설정하였다.
- activation: 활성화 함수를 의미한다. ReLU 함수가 일반적으로 다른 활성화 함수와 비교했을 때, 효율성과 성능에서 우수하기 때문에 ReLU로 설정한다.
- input_shape: 입력 데이터의 크기이다. mnist 이미지는 세로, 가로가 28이고 흑백 색상이기 때문에 채널 1을 추가한다.
- name: 무슨 레이어인지 알 수 있게 이름을 추가한다.
- MaxPooling2D: 최대 풀링을 적용한다.
- (2, 2): 풀링 크기를 (2, 2)로 설정한다. (2, 2)로 설정하면 이미지의 크기를 절반으로 줄일 수 있다. 이보다 더 큰 (3, 3), (4, 4) 등으로 설정할 수 있지만 mnist와 같은 작은 이미지에 풀링 크기를 크게 설정하면 출력 크기가 줄어드는 것과 동시에 특성맵의 중요 정보가 생략되어 출력될 수 있다.
- Flatten(): 특성맵을 1차원으로 변환시키기 위해 Flatten() 레이어를 추가한다. 1차원 벡터로 변환된 후 Dense 레이어에서 사용할 수 있게된다.
- Dense(): mnist의 정답은 0~9 사이로 총 9개의 정답 레이블이 존재한다. 그렇기 때문에 노드 개수를 10개로 설정하고 활성화 함수는 softmax로 설정한다.
2. 모델 컴파일(Compile)
# 모델 컴파일
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
정의된 모델 구조를 바탕으로 컴파일을 진행하면 모델 객체가 생성된다.
- compile(): 모델 학습 과정을 설정하는 메서드로 optimizer, loss, metrics 등을 지정한다.
- optimizer = ‘adam’: optimizer를 adam으로 지정한다. adam은 SGD(확률적 경사하강법)을 개선한 알고리즘으로 다양한 데이터셋에서 좋은 성능을 보이기 때문에 주로 사용된다.
- loss = ‘sparse_categorical_crossentropy’: 다중 분류에 사용되는 손실 함수이다.
- metrics=[’accuracy’]: 평가 지표를 나타낸다. mnist같은 다중 클래스 분류 문제는 accuracy(정확도)가 가장 직관적인 성능 지표이기 때문에 주로 사용한다. accuracy는 예측한 결과가 실제 결과와 일치하는 비율을 나타낸다.
3. 모델 학습
# 모델 학습
model.fit(x_train, y_train, validation_data = [x_test, y_test], epochs=5)
"""
Epoch 1/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 31s 16ms/step - accuracy: 0.8876 - loss: 0.4019 - val_accuracy: 0.9743 - val_loss: 0.0900
Epoch 2/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 40s 16ms/step - accuracy: 0.9749 - loss: 0.0825 - val_accuracy: 0.9793 - val_loss: 0.0673
Epoch 3/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 42s 16ms/step - accuracy: 0.9824 - loss: 0.0599 - val_accuracy: 0.9794 - val_loss: 0.0621
Epoch 4/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 29s 15ms/step - accuracy: 0.9853 - loss: 0.0494 - val_accuracy: 0.9818 - val_loss: 0.0550
Epoch 5/5
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 29s 15ms/step - accuracy: 0.9880 - loss: 0.0394 - val_accuracy: 0.9822 - val_loss: 0.0556
"""모델 객체를 바탕으로 fit() 메서드로 모델을 학습시킨다. fit()에 학습 데이터와 검증 데이터를 주입하고 학습의 반복 횟수를 지정한다. epoch가 증가할수록 정확도가 증가하고 손실이 줄어들며 학습이 진행되는 것을 확인할 수 있다.
4. 모델 평가
# 모델 평가
model.evaluate(x_test, y_test)
"""
313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 5ms/step - accuracy: 0.9792 - loss: 0.0674
[0.055618297308683395, 0.982200026512146]
"""evaluate() 메서드로 검증 데이터에 대한 정확도와 손실 등 최종 평가 지표를 출력한다.
5. 평가 결과 시각화
그래프로 시각화를 하면 각 epoch별 accuracy와 loss값을 한눈에 쉽게 파악할 수 있다.
def plot_loss_acc(history, epoch):
loss, val_loss = history.history['loss'], history.history['val_loss']
acc, val_acc = history.history['accuracy'], history.history['val_accuracy']
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(range(1, epoch + 1), loss, label='Training')
axes[0].plot(range(1, epoch + 1), val_loss, label='Validation')
axes[0].legend(loc = 'best')
axes[0].set_title('Loss')
axes[1].plot(range(1, epoch + 1), acc, label='Training')
axes[1].plot(range(1, epoch + 1), val_acc, label='Validation')
axes[1].legend(loc = 'best')
axes[1].set_title('Accuracy')
plt.show()
plot_loss_acc(history, 5)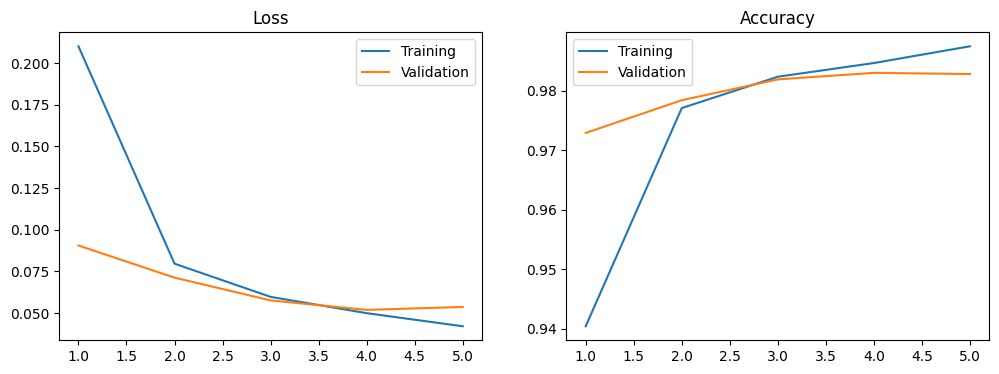
6. 모델 구조
model.summary() # 모델 구조
"""
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ conv (Conv2D) │ (None, 26, 26, 32) │ 320 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ pool (MaxPooling2D) │ (None, 13, 13, 32) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ flatten (Flatten) │ (None, 5408) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense (Dense) │ (None, 10) │ 54,090 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 163,232 (637.63 KB)
Trainable params: 54,410 (212.54 KB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 108,822 (425.09 KB)
"""summary() 메서드로 신경망 모델의 구조를 요약하여 출력한다.
- Layer Type: 쌓인 층의 구조
- Output Shape: 출력 형태
- Params: 파라미터의 수
- Total Params: 모든 층에서 학습해야 할 파라미터의 수
summary() 를 통해 제공되는 데이터를 바탕으로 모델을 개선하여 학습 효율성을 최적화할 수 있다.
7. 모델 예측
y_pred = model.predict(x_test) # 모델 예측 결과
print(y_pred)
print(y_pred.shape)
"""
313/313 ━━━━━━━━━━━━━━━━━━━━ 2s 7ms/step
[[4.9107309e-09 1.6159106e-08 1.1883390e-07 ... 9.9997944e-01
8.7521030e-09 6.6772816e-07]
[4.8825694e-07 2.0708734e-05 9.9993032e-01 ... 1.2440364e-12
8.4607126e-07 6.5673321e-11]
[4.6668480e-05 9.9831253e-01 7.5326825e-05 ... 5.0838705e-04
2.3469173e-04 1.0063005e-06]
...
[1.1618688e-11 1.6372365e-10 5.5661680e-11 ... 4.0520990e-06
3.7992613e-06 7.5990188e-06]
[1.6087787e-08 3.1592548e-10 8.9641551e-11 ... 5.2816213e-10
1.6378953e-04 1.1902936e-08]
[8.5906571e-10 1.2478392e-13 2.2528720e-08 ... 2.5092617e-11
6.4120806e-09 9.5857491e-13]]
(10000, 10)
"""이렇게 학습된 모델은 predict() 매서드를 통해 예측 결과를 확인할 수 있다. predict() 메서드에 검증 데이터를 추가하면 검증 데이터에 대한 예측 결과를 반환한다.
print(y_pred[0])
y_pred_classes = np.argmax(y_pred[0])
print(y_pred_classes) # 예측 결과값
"""
[4.9107309e-09 1.6159106e-08 1.1883390e-07 1.9715770e-05 9.8276871e-09
8.6599061e-10 1.6487920e-14 9.9997944e-01 8.7521030e-09 6.6772816e-07]
7
"""y_pred의 첫 번째만 출력하면 10개의 숫자가 numpy array 타입으로 출력된다. 순서대로 정답 레이블인 0부터 9까지의 확률 분포를 나타낸다. 이중에서 가장 높은 확률을 가진 클래스를 추출하여 최종 예측 클래스로 변환시켜 출력하면 예측 결과를 확인할 수 있다.
8. 예측 결과 시각화
import numpy as np
# 테스트 데이터에서 예측 수행
y_pred = model.predict(x_test) # 모델 예측 결과
y_pred_classes = np.argmax(y_pred, axis=1) # 가장 높은 확률을 가진 클래스 추출
# 올바르게 예측한 경우
correct_indices = np.where(y_pred_classes == y_test)[0]
# 잘못 예측한 경우
incorrect_indices = np.where(y_pred_classes != y_test)[0]
def show_res(list):
plt.figure(figsize=(10, 5), constrained_layout=True)
for i, idx in enumerate(list):
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[idx].reshape(28, 28), cmap='gray')
plt.title(f"True: {y_test[idx]} \\n Pred: {y_pred_classes[idx]}")
plt.axis('off')
plt.show()
print('True Data')
show_res(correct_indices[:10]) # True 데이터 처음 10개만 시각화
print('\\n False Data')
show_res(incorrect_indices[:10]) # False 데이터 처음 10개만 시각화올바르게 예측한 결과와 잘못 예측한 결과를 시각화 한 코드이다. 잘못 예측한 결과는 데이터셋이 애매한 경우에 잘못 예측한 것을 확인할 수 있다. 이를 개선하려면 데이터셋에 기울기, 회전, 왜곡 등을 추가하여 학습 데이터의 다양성을 증가시키는 등의 방법을 통해 모델을 개선해 나갈 수 있다.


참고 사이트:
https://colab.research.google.com/drive/1TrnjTMf3ANU9DNKNjCa-IlCBC74DoNnZ?usp=sharing
CNN Simple.ipynb
Colab notebook
colab.research.google.com
https://keras.io/examples/vision/mnist_convnet/
Keras documentation: Simple MNIST convnet
► Code examples / Computer Vision / Simple MNIST convnet Simple MNIST convnet Author: fchollet Date created: 2015/06/19 Last modified: 2020/04/21 Description: A simple convnet that achieves ~99% test accuracy on MNIST. ⓘ This example uses Keras 3 View
keras.io
https://phsun102.tistory.com/195
딥러닝 - 합성곱 신경망(CNN)
합성곱 신경망(Convolution Neural Network)합성곱 신경망은 데이터가 가진 특징들의 패턴을 학습하는 알고리즘으로 이미지나 영상 데이터를 처리하는데 주로 사용된다. 이를 사용하는 예시로는 이미
phsun102.tistory.com
'AI > Deep Learning - Machine Learning' 카테고리의 다른 글
| AI - tensorflow 전처리 함수를 활용한 연산 최적화 (0) | 2025.01.01 |
|---|---|
| AI - Dropout을 통한 과대적합 방지 (0) | 2025.01.01 |
| 딥러닝 - 합성곱 신경망(CNN) (0) | 2024.12.27 |
| 머신 러닝 - California Housing Price Prediction(Regression) (0) | 2024.08.18 |
| 머신 러닝 - IQR 이상치(Outliers) 제거 (0) | 2024.08.17 |



